
Navigando su internet ed in particolare sui motori di ricerca, molte volte ci chiediamo come sia possibile che essi conoscano tutti i siti web presenti nel mondo. Per rispondervi a questa domanda, oggi parleremo di ciò che vi si nasconde dietro le quinte il cosiddetto Crawler o spider.
Questo Crawler è un script molto potente in grado di visionare ed Indicizzare(inserire nell’indice), ad una determinata ora del giorno, tutti i siti web presenti all’interno dei server. Per rendere più chiaro il tutto immaginiamo il web come una grossa ragnatela piena di punti(siti web), dove il ragno virtuale ogni giorno attua un controllo per scoprire ogni minimo cambiamento.
Ogni motore di ricerca ha un suo crawler personale di seguito cito i più importanti.
Nome Crawler
| Googlebot | |
| Fast | Fast – Alltheweb |
| Slurp | Inktomi – Yahoo! |
| Scooter | Altavista |
| Mercator | Altavista |
| Ask Jeeves | Ask Jeeves |
| Teoma agent | Teoma |
| Ia archiver | Alexa – Internet Archive |
| Yahoo! Slurp | Yahoo |
| Romilda | |
| DuckDuckBot | DuckDuckGo |
Nonostante questo robot virtuale compia la sua azione di scouting dei siti autonomamente, a volte può accadere che il nostro sito sia talmente confusionario da non permettere al robot di capire la gerarchia delle pagine all’interno. In questo caso può succedere che nella SERP ( pagina dove appaiono i risultati della ricerca), venga visualizzato solo il dominio principale, ma non i sottodomini.
Per risolvere questo inconveniente ogni Crawler si affida a due file fondamentali per il nostro sito: robot.txt e sitemap.xml.
- Il robot.txt ha al suo interno delle righe di codice che spiegano al Crawler quale pagine può o non può vedere, seguito dal link dove è presente il sitemap.xml.
- Il sitemap.xml contiene le informazioni fondamentali per far capire al robot la gerarchia delle pagine e la loro importanza.
Quando si crea un nuovo sito web questi due file potrebbero non esserci. Considerata la loro importanza, vediamo quindi come crearli.
Se utilizzate WordPress o altri CMS non vi è nessun problema per il sitemap, in quanto è possibile scaricare dei comodi plugin che creano la nostra gerarchia automaticamente. Nel caso di WordPress, il migliore attualmente in uso è senza dubbio Yoast.
Per la creazione del robot.txt che inseriremo nella pagina principale del nostro sito, abbiamo bisogno di creare un file di testo come il seguente:
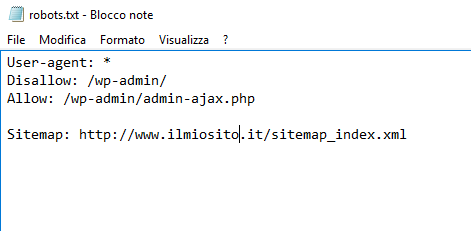
In User-agent bisogna inserire il nome dei Crawler che possono visitarci. Se desiderate che siano tutti lasciate l’asterisco. In Disallow e Allow bisogna specificare il percorso delle pagine da nascondere o rendere visibili. Infine come vedete va inserito il link dove è presente la Sitemap creata precedentemente con il plugin.
Fatto questo dopo un paio di giorni il motore di ricerca, qualunque esso sia, inserirà il vostro sito nel suo indice e consentirà al vostro sito, con i sottodomini annessi, di essere visibile nei risultati dei motori di ricerca.